What’s Your DEQ? Why Data Empathy Is Essential For Health Data Impact

David Shaywitz
“Their story — yours, mine — it’s what we all carry with us on this trip that we take, and we owe it to each other to respect our stories and learn from them.” — Dr. William Carlos Williams to Dr. Robert Coles, from Coles’s “The Call of Stories.”
The term “data empathy” is on the verge of entering the mainstream. It’s about time.
At least in print, the concept of “data empathy” was introduced in a 2014 paper by James Faghmous and Vipin Kumar, on climate science. One of the most significant challenges of working with “big data,” the authors write, is that, “with large datasets where one measures anything and everything, it can be difficult to understand how that data were collected, and for what purpose.”
This matters, the authors eloquently argue, in the most important sentence of the paper:
“Every dataset has a story, and understanding it can guide the choice of suitable analyses.”
This understanding, the broader contextual background surrounding the data collection and analysis, is termed “data empathy.”
There are two important reasons to seek out the story behind data, continue Faghmous and Kumar:
“[F]irst, understanding how the data are generated, their purpose, and generation processes will guide your investigation. Second, understanding the inherent biases in the data gives you the chance to correct them or adjust your results and recommendations.”
Yes, yes, a thousand times yes.
The most significant challenge faced in learning from “big data” in health is the disconnect between those generating the data and those trying to apply analytics to learn something from these data. Nearly everything worthwhile in health is complicated and messy, from biology to healthcare delivery (see here, here, here).
It’s appealing (for some) to imagine the intrinsic messiness can be offset by data volume or smart analytics, or that if you just stick all your assorted information in a giant digital vat, you can generate brilliant insights simply by letting data geeks, AI, or both, push and pull at it until it’s tortured into submission.
Bashing at data you don’t deeply understand is futile at best, and often dangerously misleading, because you can always calculate something. The question is whether what you’re doing is meaningful or simply digital onanism.
I’ve recently discussed in TR why learning from EHR data, challenging under the best of circumstances, requires a sophisticated understanding of the local clinical practices associated with the data you’re examining; absent this knowledge, your conclusions are likely to be naïve, misguided, and quickly dismissed.
This has profound implications for healthcare and pharma organizations building out data science teams, as so many are right now. To cut to the chase: unless you recognize the foundational importance, as an organizing principle, of data empathy, and select your team with this vital and often elusive capability in mind, you’re going to have a really difficult time both gaining critical organizational traction and delivering meaningful insights. You will risk being regarded as just the innovation flavor of what promises to be a very short moment.
Many supposedly brilliant data scientists, arriving with impeccable technology credentials (think “best of the best of the best, sir”), have enjoyed remarkably short tenures in healthcare organizations – attributable, I’d argue, to a low DEQ – data empathy quotient.
Conversely, leaders who’ve most effectively marshaled health data science to solve organizational challenges – Dr. Amy Abernethy’s work at Flatiron obviously comes immediately to mind – have extremely high DEQs. Other conspicuous examples of high DEQ at work include Dr. Omri Gottesman’s early contribution to Regeneron’s data integration platform, and Dr. Griffin Weber’s work in the academic sector.
The integrative ability at the heart of data empathy must reside in and reflect the philosophy of the entire data science team, as well as be embodied by the team’s leadership. The data science team must recognize, and must, critically (this is the biggest challenge), persuade the organization that data scientists do not and will not succeed by staring at a computer screen and delivering insights on datasets they’ve been handed.
The organization must not be conditioned to expect this over the transom approach, either. Instead, skilled data scientists work closely and collaboratively with front-line colleagues, including physicians and drug developers, who are generating the data, and with colleagues who are seeking greater insight from the data (the two groups might not be the same, but could be).
The point is that whether in a pharma company or a healthcare system, only by deeply understanding the nuance of how the data were generated, and having a sense of the anticipated use — and by being innately curious about both — can health data scientists function effectively, and deliver relevant results and meaningful insights.
Fortunately, there are at least two reasons for real hope: first, data scientists, as I’ve described in both a recent Wall Street Journal book review and in TR, are increasingly attuned to the shortcomings in their datasets, and are (now) exceptionally attuned to issues of bias and equity. The idea that even – especially – large datasets need to be scrutinized with particular care is now dogma among leading data scientists, who recognize data doesn’t exist, and can’t be assumed to exist, on some pure, objective plane. The increased attention to how data are generated will be especially valuable for healthcare data science.
Second, and perhaps most importantly, there are ever-more inquisitive physicians and biomedical scientists who are captivated by, and often trained in, data science. I grew up running gels in traditional wet labs (how quaint), but today’s inquisitive physicians and scientists are as likely to be crunching data at multiple desktop monitors.
These emerging health data scientists are more apt to recognize that all data aren’t equally suitable for all analyses, and to realize how important it is, as you’re collecting and organizing your data, to have a clear sense of what sort of things you hope to learn from it. Done right, in collaboration with providers and scientists who are closest to the problems, it’s possible to create a positive feedback loop in which data scientists get more clarity on the problems to solve, and front-line stakeholders appreciate the insights and values high DEQ data scientist teams can bring.
Bottom line
The successful application of data science to healthcare delivery and drug development requires a high DEQ, an awareness of, and innate curiosity around the context in which data are generated. Data science teams in healthcare organizations foundationally require data empathy. The increased humility and self-reflection within the field of data science, and the increased focus of inquisitive biomedical researchers on data science questions, both represent hopeful signs for the future of health data science.








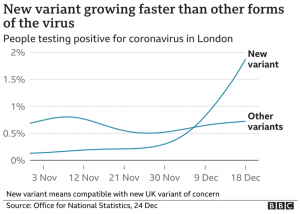
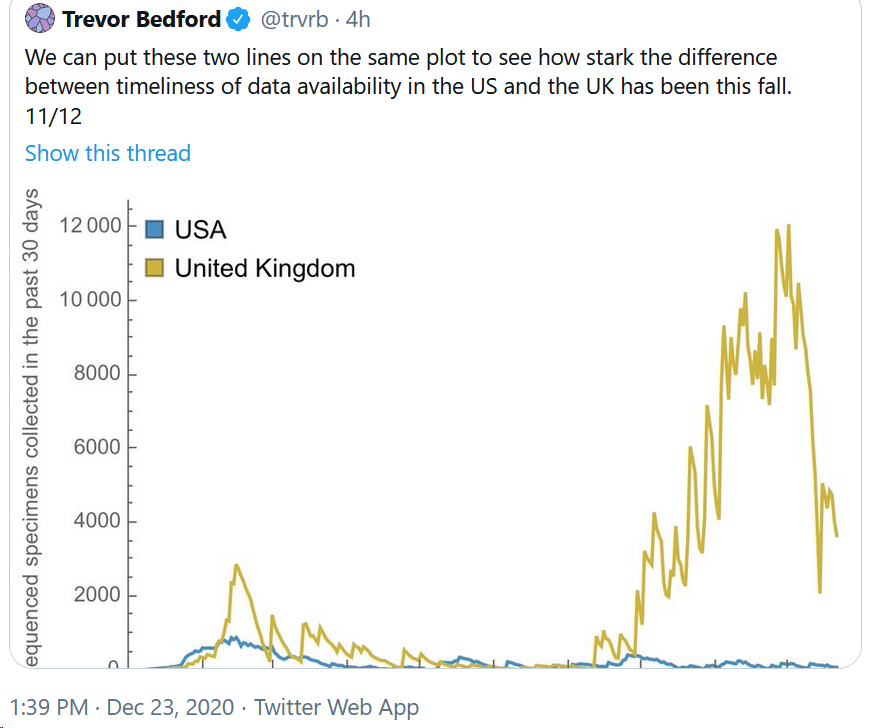
 All mutations that are incorporated into virus strains that spread out geographically and grow faster than their predecessors are a “smoking gun”. This is exactly what has happened in the United Kingdom over the past three months and may be happening again in South Africa. The most recent analysis of the UK strain (B.1.1.7; aka VOC-202012/01; aka 20B/501Y.V1) combines prior laboratory findings (
All mutations that are incorporated into virus strains that spread out geographically and grow faster than their predecessors are a “smoking gun”. This is exactly what has happened in the United Kingdom over the past three months and may be happening again in South Africa. The most recent analysis of the UK strain (B.1.1.7; aka VOC-202012/01; aka 20B/501Y.V1) combines prior laboratory findings (